Project Proposal
Milestones ·Here, we briefly describe the project proposal as given by the guidelines.
| Title: | Parallelized PCYK Algorithm for Syntactic Parsing |
| URL: | https://thepulkitagarwal.github.io/pcyk/ |
| Members: | Ansong Ni (ansongn) & Pulkit Agarwal (pulkitag) |
Summary
In this project, we aim to parallelize the PCYK parsing algorithm for syntactic parsing on Nvidia GPUs (for CUDA) and Multicore Machines (for OpenMP / Cilk).
Background
The Probabilistic Cocke-Kasami-Younger algorithm (PCYK1) algorithm is a dynamic programming algorithm for parsing sentences with Chomsky Normal Form (CNF).
An illustration of the PCYK algorithm for syntactic parsing for a natural language sentence “Fish people fish tanks” is shown like in the figure below.
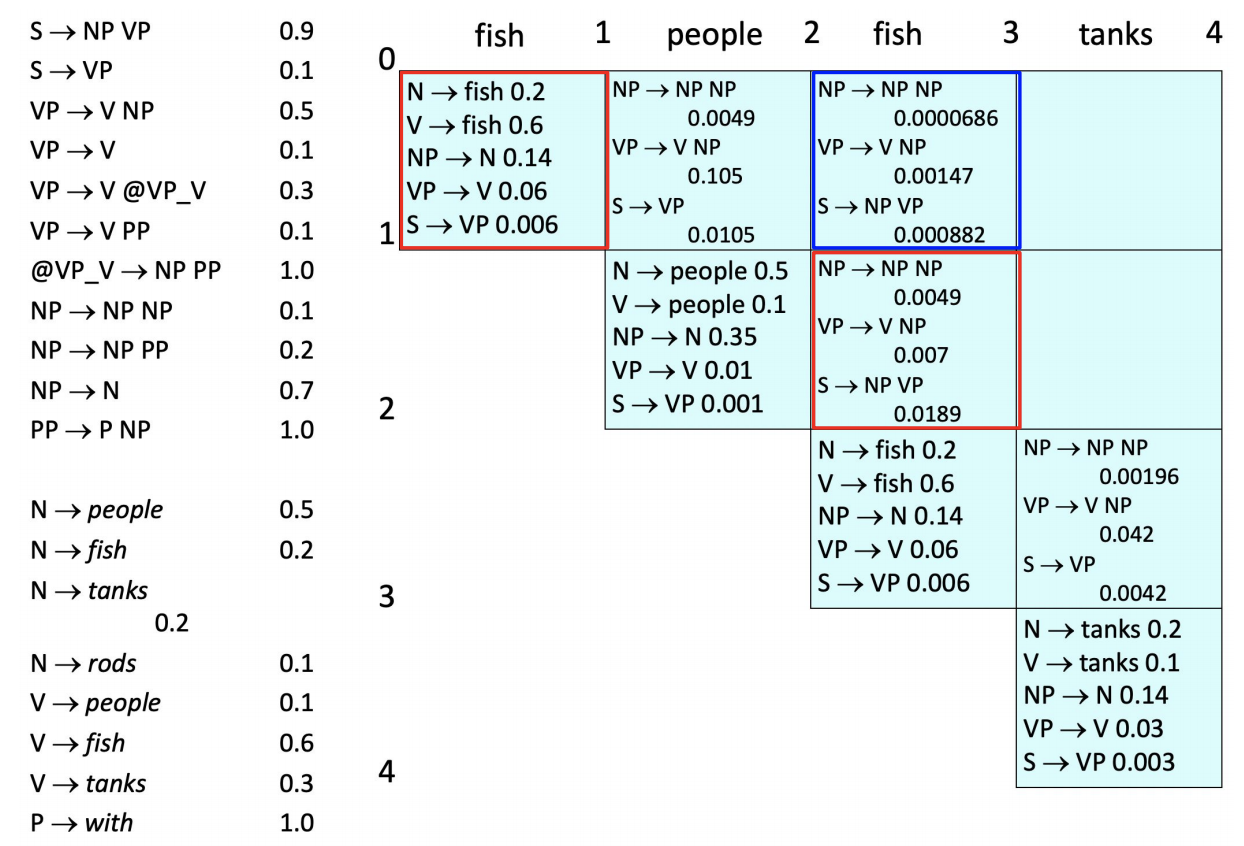 |
|---|
| Figure 1: An example of the PCYK algorithm for syntactic parsing2 |
It is a bottom-up algorithm that iteratively builds up the binary parse tree from the words as terminal (i.e. leaf) nodes. The appearance binary and unary parse rules are counted during the training time so it could be used to estimate the probability of a parse tree at test time. After performing the PCYK parsing and obtaining the parsing chart, the best parse tree is generated through a greedy search of the most probable child from the root node.
Different parts of this algorithm can benefit from parallelism, which we will describe with more detail in the challenges section.
The Challenges
- The dependencies for computation are rather complicated. Thus we are left with plenty of opportunities to design the order of computation to maximize parallelism. Since it is a bottom-up algorithm, computation for the upper level tree nodes depend on some of the lower level tree nodes. Moreover, the completion of nearby tree nodes makes it possible to start computation for upper level nodes that only depend on those nodes, without waiting for the whole level to complete.
- The workload from level to level is not uniform, which makes it challenging for us to design a strategy for load-balancing during the parsing.
- The initial training procedure involves counting the appearance of production rules which can be done in many ways, but we need to consider the trade-off between speed, memory and accuracy across various parallel paradigms (i.e. with or without locks, storing the count in shared memory or local memory, etc).
- The parsing process on a test set can be trivially parallelized by data parallelism with each thread keeping a copy of the probability for parse rules. However, when considering different parallel architecture (i.e. CUDA, OpenMP, etc), we need to investigate whether this strategy is actually beneficial due to bandwidth and memory constraints.
- There are multiple extensions to PCYK algorithm, which improves the accuracy of the parsing but also makes the algorithm more complicated and thus harder to parallelize. So if time permits, we can investigate how to parallelize the algorithm with those tricks to make it fast and robust.
Goals
Plan to Achieve
For the CUDA Implementation of the PCYK Algorithm, the paper Efficient Parallel CKY Parsing on GPUs by Yi et. al. achieves 26x speedup. We aim to achieve a similar speedup on the GHC machines.
Hope to Achieve
- Try to beat the 26X speedup on CUDA achieved by the paper.
- OpenMP / Cilk Implementation of PCYK Algorithm.
Deliverables
- Sequential Implementation of PCYK Algorithm (C++)
- CUDA Implementation of PCYK Algorithm
- (Hopefully) OpenMP / Cilk Implementation of PCYK Algorithm
Poster Session
- Speedup Graphs
- Live Demos / Outputs of our CUDA implementation (depending on the state of the GHC machines that day)
Platform Choice
We plan to use CUDA (GPU Architecture) and OpenMP / Cilk (Shared Memory Multicore Architecture).
Resources
- For understanding the PCYK algorithm, we plan to use the CMU Algorithms for NLP course and the wikipedia article on CYK as reference.
- For help with PCYK on CUDA, we will use the paper Efficient Parallel CKY Parsing on GPUs by Yi et. al. as a reference for our implementation.
- We also will be using the CMU 15-418 Course as reference. More specifically, we will be using the CUDA Slides and Cilk Slides among others, and the CUDA Assignment and the OpenMP Assignment as well.
Hardware Resources
The main resource we would require are Nvidia GPUs (for CUDA) and Multicore Machines (for OpenMP / Cilk). We believe that the GHC machines we used for our assignments should be good enough for our project.
Planned Schedule
| # | Dates | Plan |
|---|---|---|
| 1 | Oct 27 - Nov 02 | Meeting with Course Instructors, Project Proposal |
| 2 | Nov 03 - Nov 09 | Sequential Version of PCYK |
| 3 | Nov 10 - Nov 16 | Cuda Version of PCYK |
| 4 | Nov 17 - Nov 23 | Optimizations in the Cuda Version of PCYK |
| 5 | Nov 24 - Nov 30 | Optimizations in the Cuda Version of PCYK |
| 6 | Dec 01 - Dec 07 | Hope to Achieve Goals |
| 7 | Dec 08 - Dec 10 | Final Report + Poster Session |
-
The PCYK algorithm is also known as the CYK algorithm or the CKY algorithm in the NLP Community. ↩
-
Example borrowed from the slides of the CMU Algorithms for NLP course. ↩